Jeg har for nylig lavet en simpel vejledning ved hjælp af det sjove hundeprotokol-datasæt fra Danmark i det 19. århundrede, som jeg har haft lyst til at dele.
Denne vejledning var oprindeligt til mit foredrag på University of Edinburgh Centre for Data, Culture & Society: Færdigheder i Heritage Data Science: Mød hundene i Danmark i det 19. århundrede den 13. januar 2021. En optagelse af foredraget kan ses på CDCS’ hjemmeside.
Du er velkommen til at prøve vejledningen i Google Colab-arbejdsbogen eller downloade den til senere brug. Den er licenseret med CC BY 4.0 og kan findes her: https://colab.research.google.com/drive/1M6pM9orJzg9CuSPYVpmfFY6Svv_RgkHN?usp=sharing
Ideen med denne vejledning er at vise, hvor få trin der skal til i Python for at begynde at visualisere og forstå et kulturarvsdatasæt.
Baggrunden for dette datasæt er et register over hundeejere i Kolding i Danmark i det 19. århundrede. I 1824 indførte Danmark et system med hundetegn til borgerne i byerne – hvis en hund ikke bar et hundetegn, kunne den blive aflivet af frygt for rabies.

by Hoffgaard 1895

by Hoffgaard 1895

by Hoffgaard 1896.
Selvfølgelig skulle nogen stå for at udlevere hundetegn og tage imod betaling (1 rigsdaler), og denne transaktion skulle registreres i en protokol. Politiet i de forskellige byer lavede disse registre, men det er forskelligt fra sted til sted og fra tid til anden, hvilke oplysninger de skrev ned. Faktisk er det nok mest forskelligt fra person til person. Ud over ejerens navn, og om de havde betalt det pågældende år, registrerede nogle også hundens navn, dens race (hunderace), farve (farve), køn (køn), alder (alder) og andre egenskaber ved hundene. Men det blev gjort på en ret tilfældig måde.
Datasættet med protokoller indeholder 1232 rækker data, som er blevet transskriberet som en del af et projekt med min 2019-klasse om digital arv på Københavns Universitet. Protokollerne begynder i 1824 og slutter i 1874. De studerende var ansvarlige for nogle få sider fra protokollerne og fik hjælp fra frivillige samfundshistorikere på Facebook. I klassen brugte vi protokollerne som en case til at udforske oprettelse, organisering og kommunikation af kulturarvsdatasæt. Baseret på datasættet lavede vi et Entity Relationship Diagram og strukturen i en relationsdatabase i MySQL samt både low- og high-fidelity prototyper af et website til at kommunikere datasættet til specifikke brugergrupper.
Datasættet i sin rå dataform kan findes på Github som en CSV-fil med 1232 rækker og 19 kolonner:

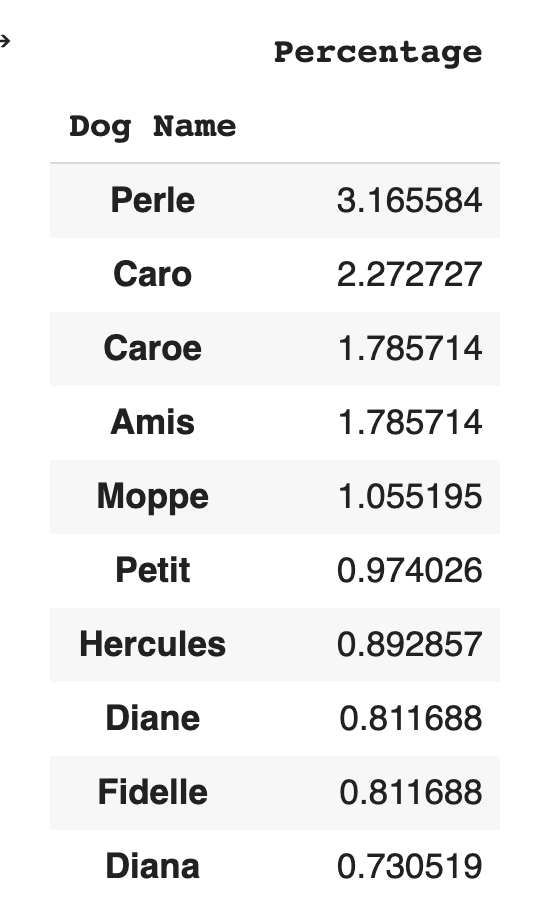
Vejledningen viser tre måder at visualisere noget af datasættet på. Den første beregner hundenavnene og præsenterer top 10-navnene. Dette viser, at det mest populære hundenavn i datasættet er “Perle”, som betyder perle på dansk.
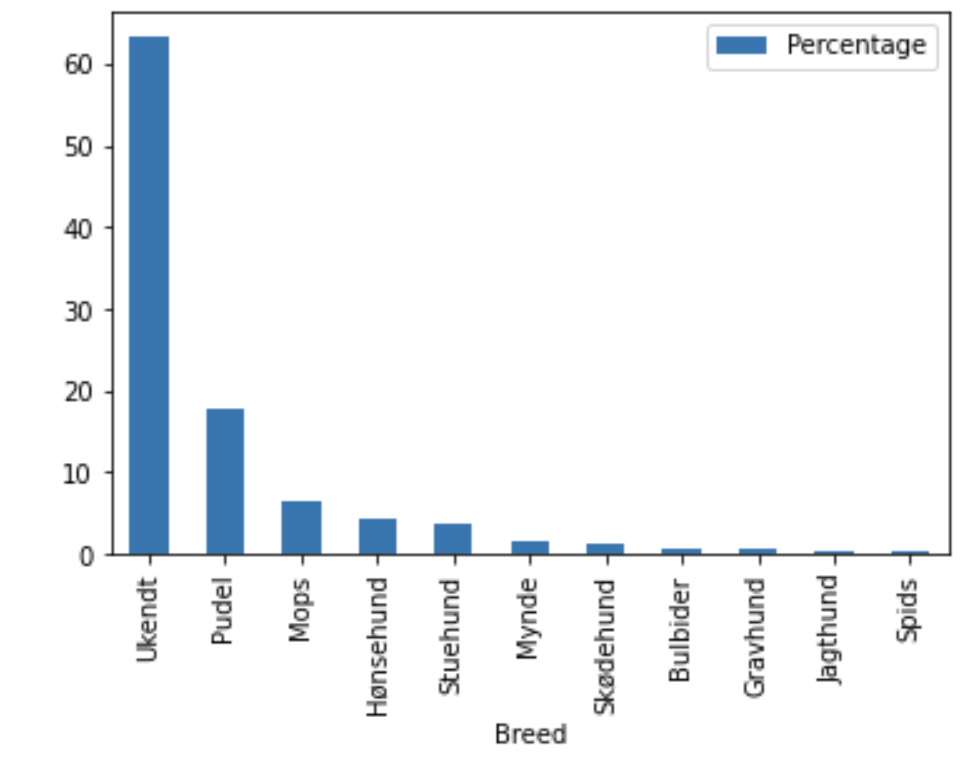
Den anden er en visualisering af procentdelen af hunderacer i datasættet, som viser, at de fleste hunde har en ukendt race (ukendt). Den mest populære kendte hunderace er puddel (Pudel) med 17,6 %, og den næstmest populære kendte race er mops (Mops) med 6,3 %.
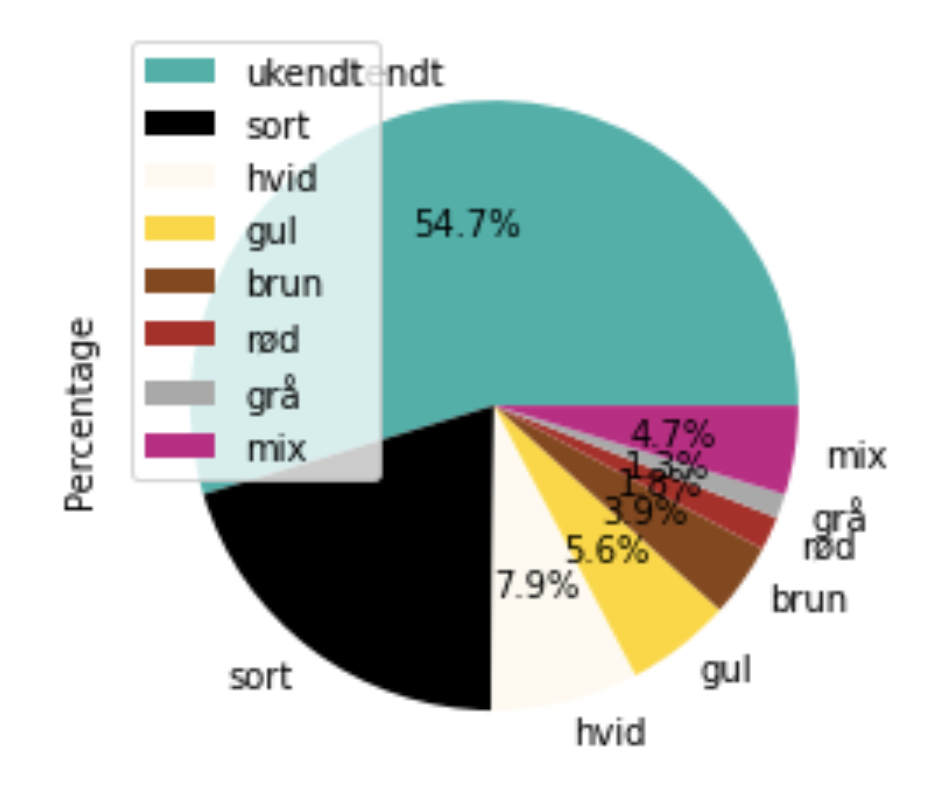
Den sidste er en visualisering af hundefarverne i et cirkeldiagram. Igen er de fleste af hundene en ukendt farve (blågrøn), og næsten 5 % er en blanding af farver (pink). Resten vises med den rigtige farve i diagrammet, hvor sort er den største kategori med 20 %.
Hvis du er interesseret i åbne kulturarvsdata, kan du læse mere om min bog i detteindlæg.
Som altid vil jeg meget gerne høre, hvad du mener om dette emne på Twitter, LinkedIn eller via e-mail.